Principal Component Analysis
- 주성분 분석은 최대 분산 순으로 특징을 나열함으로써 차원축소하는 비지도학습이다.
- 변수 사이 상관관계 있을때
Refernece: 핸즈 온 머신러닝, 최규빈교수님 통계전산강의노트 사이킷런 홈페이지
차원 축소
차원 축소가 필요한 이유
- 특성이 너무 많으면 차원의 저주 curse of dimensionality 에 빠지게 된다.
차원 축소를 위한 접근 방법
- ex) 3d 공간 안에 있는 저차원 부분 공간 subspace이 있는데 여기에 수직1 투영하면 평면에 투영된 좌표를 얻음.
- ex) 아래 그림 처럼 부분 공간 subspace가 휘어있기도 함.(swiss roll 예제) 오른쪽은 왼쪽의 스위스 롤을 펼쳐서 2D 데이터 셋을 얻은 것임.

- 위 스위스 롤 예제는 2D 매니폴드의 한 예
- 매니폴드를 펼쳐서 보느냐, 어떻게 경계선을 그어서 보느냐 등 저차원의 매니폴드 공간에 가깝게 놓여있다고 가정2
- 저차원으로 차원축소 할 수 있지만, 오히려 복잡해지는 경우3도 있다.
\(\star\) 2D 매니폴드는 곡선, 3D 매니폴드는 곡면이라 생각

PCA
주성분 분석 principal component analysis
PCA is a statistical technique for reducing the dimensionality of a dataset.
1. 분산 보존
분산이 최대로 보존되는 차원 축소가 정보를 가장 적게 손실되어 합리적으로 보임
2. 주성분
분산이 큰 순서대로 차원의 수만큼 찾음
i번째 축 = 주성분 PC principal component
특이값 분해 SVD singular value decomposition= training set에서 주성분 찾는 방법
- 이론 : \(X_{n \times m} = U_{n \times n} D_{n \times m} (V_{m \times m})^\top\)
- ver 1 = \(U, V\)가 모두 직교 행렬
- ver 2 = \(U\) 또는 \(V\)가 직교 행렬
- 왜?
- 데이터 매트릭스 \(X\)가 존재할때 정보는 유지하면서 비용을 줄이는 \(Z\)4를 찾고 싶다.
- \(Z\) 구하는 법
- \(Z = \tilde{U} \tilde{D}\) \(\to\) \(\tilde{U} \tilde{D} = X\tilde{V}\) \(\to\) \(Z = X\tilde{V}\)
- \(X^\top X = \psi \lambda \psi^\top\)을 구해서 \(Z = X\tilde{\psi}\) \(\to\) \(\hat{X} = Z\tilde{\psi}^\top\)
\(\star\) PCA는 데이터셋의 평균이 0이라고 가정
3. d차원으로 투영하기
\(X_{d-proj,n \times d} = X_{n \times M} W_{d,n \times d}\)
4. 설명된 분산의 비율
설명된 분산의 비율 explained variance ratio
- 공분산 행렬의 고유값
- 투영한 분산의 비율
- 주성분 선택된 순으로 작아짐
5. 적절한 차원 수 선택하기
차원 수를 임의로 정하는 것보다는 충분한 분산5이 될 떄까지 선택
6. 압축을 위한 PCA
중요한 특징만을 살리기 위해 PCA를 시도하여 차원 축소하였다.
이후 원본 데이터로 돌아가려 할 때 특징은 살아있지만 완벽히 데이터셋이 일치하지 않는데,
여기서 이 오류를 재구성 오차 = 재건 오류 reconstruction error 라고 한다.
\(X_{n \times M} = X_{d-proj,n \times d} (W_{d,n \times d})^\top\)
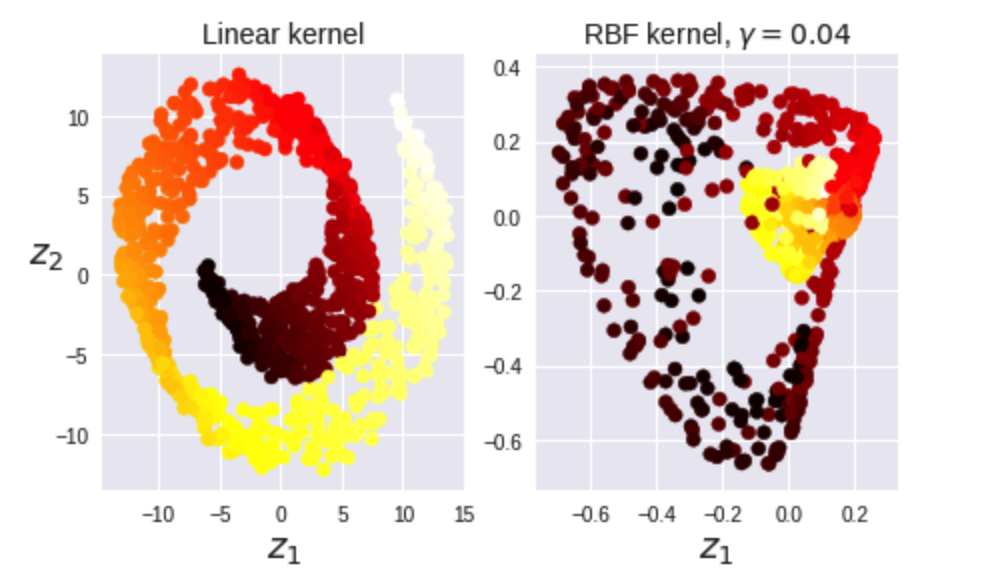
7. 커널 PCA
차원 축소를 통해 비선형 투영 수행
\(\zeta = \Psi \alpha\)
- 이 때, \(||\alpha_j|| = 1\)로 정규화한다.
- 그러기 위해 \(\alpha_j\)를 \(||\zeta_j||\)로 나누어 정규화
- \(||\zeta_j|| = \sqrt{\lambda}_j\)
- \(\alpha_j \to \frac{1}{\sqrt{\lambda}_j} \alpha_j, j=1, \dots, m\)
특징 벡터로 내적하여 나오는 커널\(K\) 행렬로 중심화
- \(K = HKH\)
- \(H = I_n - 1_{n \times 1} /n\)
\(\alpha\) 정규화 한 후 중심화하면
\((z_1, \dots, z_n) = (\frac{1}{\sqrt{\lambda_1}} \alpha_1,\dots , \frac{1}{\sqrt{\lambda_m}}\alpha_m)^\top HKH\)
- 여기서 m개가 주성분!
\(\star\) 고유벡터
- 선형 \(C = \psi \psi^\top\)
- 비선형 \(K = \psi^\top \psi\)
- \(\psi\)의 길이에 따라 고유값 문제의 표현을 다르게 하여 계산 시간 줄이기
- 차원 수가 표본 수보다 큰 경우에는 커널 행렬을 사용하는 것이 효율적